
This story is about the technical challenges we faced and what we learned at HeatTransformers when rewriting our event-sourcing patterns to improve read performance by orders of magnitude.
Introduction
To explain what "The Real Deal" is and why it was necessary for us, we need to start by describing what event-sourcing is and how we used to implement it in our system.
What is Event-Sourcing
Event Sourcing is an architectural design pattern where changes that occur in a domain are immutably stored as events in an append-only log.
This provides a business with richer data as each change that occurs within the domain is stored as a sequence of events which can be replayed in the order they occurred.
We use TypeScript, MongoDB, and Prisma ORM on our backend. Our main entity in the system which represents the state of a deal with a client is called (surprise) Deal. Each Deal contains some events as a nested list. These are all the changes that happened to this Deal since its creation.
To get the most recent state of the Deal we accumulate all of the Deal's events and apply them one-by-one using MongoDB aggregation.
But before we dive into how Deal is structured, let's clear a few things. Deal is a view on another model called DealEventStream in Prisma schema. This Deal view is constructed using an aggregation on DealEventStream.
For example, here is DealEventStream:
{
"_id": {
"$oid": "678e4097ce850d2ecda12345"
},
"zohoDealId": "12345000012345678",
"events": [
{
"_id": {
"$oid": "678e4097635ed21a39c12345"
},
"type": "configure",
"data": {
"heatPumpInstallationType": "HYBRID",
"gasConsumption": 10
},
"timestamp": {
"$date": "2025-01-20T12:24:55.906Z"
}
},
{
"_id": {
"$oid": "678fb322d4f72271d6712345"
},
"type": "configure",
"data": {
"gasConsumption": 123
},
"userId": {
"$oid": "672a0ce8e74ed63a49812345"
},
"timestamp": {
"$date": "2025-01-21T14:45:54.381Z"
}
}
]
}And here is Deal view on this model:
{
"_id": {
"$oid": "678e4097ce850d2ecda12345"
},
"zohoDealId": "12345000012345678",
"config": {
"heatPumpInstallationType": "HYBRID",
"gasConsumption": 123
},
"events": [...]
}Notice how events are aggregated in the config nested object. The gasConsumption is 10 in the first event, but it is overwritten as 123 by the second event. And heatPumpInstallationType is HYBRID in config since it is the only such key between two events. There could be more events, and they would be applied the same way to construct the final view.
There are also fields outside of config, e.g. zohoDealId which is the id of the entity in our CRM. We do not event-source those fields for the performance reasons described below.
Old Aggregation
I will hide the simplified old MongoDB aggregation that we used to construct Deal view from DealEventStream documents under a spoiler, since it is not as important to the main story. But if you are curious, take a look. It is not easy to read even in this simplified form.
Slow Performance
Do you notice the downside of this approach? When we need to read the latest state of some Deal we must iterate every Deal's event, which is slow. How slow? Well, for less than 80k Deals with around 2 million events in total, the execution time was 7923 ms.
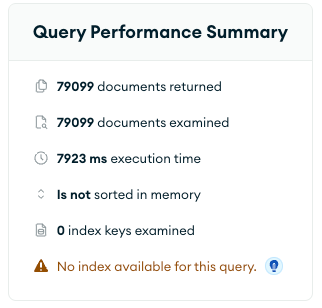
Every time we filter Deals by some field on Deal config, MongoDB needs to aggregate every DealEventStream into Deal, check that field, and then return the result. And of course, you cannot easily index aggregated fields in the config.
// Takes a lot of time
await prisma.deal.find({ where: { 'config.gasConsumption': 123 }}); For our new upcoming projects we needed the high read performance, therefore the old aggregation did not suit us. That is our motivation for the Real Deal.
Can we do better? Yes, definitely.
New Event-Sourcing Solution

What if we store the latest state of every Deal instead of aggregating it on every read? Then reads should be blazingly fast and writes just a bit negligibly slower.
In the new version of event sourcing our Deal will be a model, not a view. We will call it NewDeal so as not to confuse it with the previous view. We also introduce a new model NewDealEvent, which will contain all the events that happened to the instances of NewDeal.
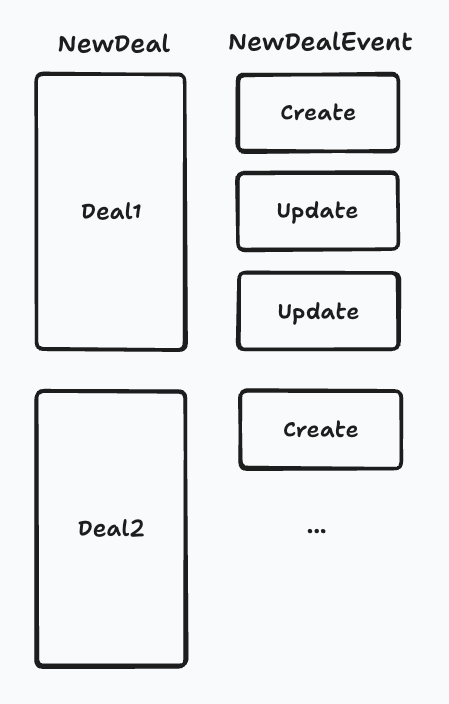
Why writes in NewDeal will be a bit slower then? Because for every update of NewDeal we will need to create a NewDealEvent document of type "UPDATE". This will rebuild some indexes on NewDealEvent but overall it is still a fast operation. The concrete benchmarks of NewDeal will be at the end of the article.
So we have a vision of the new system, but how do we migrate 80k Deals with 2M+ events to a new system without losing any data and disrupting the work? We went forward with a shadowing approach.
Shadowing
The idea behind shadowing is that we first create NewDeal and NewDealEvent collections in production and fill them with data. Then we enable writing in them alongside DealEventStream and closely monitor any errors that occur during the shadowing period. So for any DealEventStream create or update, the corresponding create or update happens to NewDeal. This gives us a chance to find bugs in the new approach and fix them before fully moving to NewDeal.
await prisma.dealEventStream.update({
where: {
id: deal.id,
},
data: {
partnerCampaignId: campaign.id,
},
});
// Temporary shadowing for Real Deal
try {
await prisma.newDeal.updateEntityAndCreateEvent({
where: { id: deal.id },
data: {
partnerCampaignId: campaign.id,
},
});
} catch (error) {
const sentryError = new SentryError('RealDeal shadowing error', 500, {
category: 'technical',
originalError: error,
level: 'error',
data: {
prismaDealId: deal.id,
partnerCampaignId: campaign.id,
},
});
Sentry.withScope((scope) => {
sentryError.enrichSentryScope(scope);
Sentry.captureException(sentryError);
});
}If anything bad happens during try-catch, we will see the error in Sentry and can quickly act upon it.
We found multiple bugs in our implementation during that phase and fixed them. For example, one bug was with transactional logic on creating and updating NewDeal. More in the next sections.
The next step is to change reading from Deal to NewDeal. Important to have a backup plan to roll this change back in case there is a critical issue. At this point the migration to NewDeal is almost finished. What's left is to backup and delete old Deal data, and rename NewDeal to Deal.
Conversion of Deals into NewDeals
To proceed with the shadowing, we need to fill NewDeal and NewDealEvent with the data first. We created a special script for this that can be run at any time on any db. We did not go for the usual database migration because we want the ability to easily re-run the script.
In this script, we need to aggregate old DealEventStreams into Deals, create NewDeals from these. Then, for each Deal create NewDealEvents. The problem is there are too many deals and events to do that in one batch; such a query would fail. The solution is to split deals and events into several batches and create data batch by batch.
The following is our initial attempt at creating deals and events. This code snippet shows the processing of one batch of 5000 deals. Can you spot the problem with this?
const BATCH_SIZE = 5000;
const newDealsPromise = prisma.newDeal.createMany({
data: newDealsToCreate,
});
const newDealEventsBatches: NewDealEvent[][] = [];
for (let i = 0; i < newDealEventsToCreate.length; i += BATCH_SIZE) {
newDealEventsBatches.push(newDealEventsToCreate.slice(i, i + BATCH_SIZE));
}
const newDealEventsPromises = newDealEventsBatches.map(batch =>
prisma.newDealEvent.createMany({ data: batch })
);
await Promise.all([newDealsPromise, ...newDealEventsPromises]);The problem is, of course, the last line. Promise.all will start a lot of connections to MongoDB at the same time. Each of these connections will try to insert a lot of entities. This can easily bring down a MongoDB cluster and make it unresponsive. This is exactly what happened to us. 🙂
We have an M10 MongoDB cluster in Atlas Cloud with auto-scaling turned on. When the cluster CPU usage reaches around 90% for 20 minutes, it starts the auto-scaling process. This works well on constant loads without spikes, but in our case, we had a costly operation that created a lot of connections to the database. So the script triggered auto-scaling, which further exacerbated the situation, and the database became unavailable.
Some deal batches were actually processed in time, but we had several big batches that caused the problem. There were at most 366k events in one of these batches, splitting them in chunks of 5k would mean at most 73 promises. These 73 promises took all of the cluster's resources.
Big shoutout to the MongoDB support team. We reached out, and they quickly resolved the issue by restarting the cluster. We then proceeded to improve the script.
Here is our final attempt:
let batchIndex = 0;
while (true) {
const deals = await prisma.deal.findMany({
take: BATCH_SIZE,
...(cursor ? { cursor: { id: cursor }, skip: 1 } : {}),
orderBy: { id: 'asc' },
});
if (deals.length === 0) break;
const newDealsToCreate = deals.map((deal) => convertDealToNewDeal(deal));
const newDealEventsToCreate = deals.flatMap((deal) =>
convertDealToDealEvents2(deal)
);
cursor = deals[deals.length - 1].id;
batchIndex += 1;
const newDealEventsBatches: any[] = [];
for (let i = 0; i < newDealEventsToCreate.length; i += EVENTS_BATCH_SIZE) {
newDealEventsBatches.push(
newDealEventsToCreate.slice(i, i + EVENTS_BATCH_SIZE)
);
}
try {
await prisma.newDeal.createMany({
data: newDealsToCreate,
});
for (const newDealEventsBatch of newDealEventsBatches) {
await prisma.newDealEvent.createMany({ data: newDealEventsBatch });
}
} catch (error) {
console.error('Error creating newDeal and newDealEvent entities:', error);
errors.push({
batchIndex,
failedDealIds: deals.map((deal) => deal.id),
error: {
message: error.message,
stack: error.stack,
},
});
}
}This is the correct way to process batched data in MongoDB. We make a paginated call to fetch deals using a cursor. A cursor here is just an ID of the last deal in the batch. Then we split the deal events in batches and await inserting them sequentially. No multiple simultaneous DB connections this time.
We try/catch here and later store the result to JSON file to make sure we keep track of every failed batch so we can re-run the script for that batch if necessary.
Worked like a charm.
Prisma Extensions
Now that we have the data in the MongoDB, time to do some operations on it. Each NewDeal creation should also create a NewDealEvent. And updates should create events too. We need to ensure the atomicity of these operations. That is when there is an error during deal creation, no event should be created, and vice versa. To ensure this, we need to do this in a transaction.
However, transactions in Prisma are not "traditional" in that sense. If you try to use prisma.$transaction to update some documents in MongoDB, it will work. But if there is a second transaction trying to update the same rows while the first is not finished, the second transaction will fail with a write conflict error. That was the complication mentioned above that we found during the write shadowing period.
But Prisma saves the day with nested queries. Nester queries are a way of creating an associated entity in one go, along with the main entity. Perfect for our goal of creating both NewDeal and NewDealEvent.
Prisma allows you to write custom extension methods for its models, which is exactly the feature that we need. We decided to use it and write our own methods that atomically create NewDeal and NewDealEvent, update NewDeal and create an event, and so on.
Creating the Extensions with Nested Queries
export type NewDealUncheckedCreateArgs = Omit<Prisma.NewDealCreateArgs, 'data'> & {
data: Prisma.NewDealUncheckedCreateInput;
};
export function createDealExtension(prisma: PrismaClient) {
return {
model: {
newDeal: {
/**
* This method creates a new NewDeal entity and a corresponding NewDealEvent of type CREATE.
*/
async createEntityAndEvent(
args: NewDealUncheckedCreateArgs,
options?: { userId?: string }
) {
return await prisma.newDeal.create({
...args,
data: {
...args.data,
newDealEvents: {
create: {
type: NewDealEventType.CREATE,
fieldChanges: args.data as InputJsonValue,
userId: options?.userId,
},
},
},
});
},
// ... other methods
},
},
};
}Notice NewDealUncheckedCreateArgs type that contains the modified data property. That is to disallow developers from using nested queries in createEntityAndEvent function calls. For example, code like this would be disallowed by the type-checker:
await prisma.newDeal.createEntityAndEvent({
data: {
contact: {
type: 'HWP',
create: {
name: 'New contact',
...
},
...
},
},
});That is to ensure developers do not create new entities in this query. That would mess up ContactEvents structure by creating a Contact entity without ContactEvent. Instead, here it is encouraged to create Contact separately and pass its id like that:
const { id } = await prisma.contact.createEntityAndEvent(...);
await prisma.newDeal.createEntityAndEvent({
data: {
type: 'HWP',
contactId: id,
...
},
});Usage of Extensions
The interface of the extensions is specifically very close to the corresponding create, update and other methods of original prisma.newDeal. So it is easy to use:
await prisma.newDeal.createEntityAndEvent({
name: 'New Deal',
type: 'HWP', // Stands for hybrid heatpump (warmtepomp in Dutch)
... other fields,
});Performance Before and After
Now we can delete the old aggregation, Deal view, and DealEventStream collections, leaving only NewDeal and NewDealEvents collections. Of course, for cleanliness sake they will be renamed to Deal and DealEvents later.
The same query that took 8 seconds now takes 204 milliseconds on new collections (39x improvement):

// Really fast now
await prisma.newDeal.find({ where: { gasConsumption: 123 }});Key Takeaways
Aggregating entity state on every read is slow
The better approach is to store the latest state of the entity, and reconstruct previous version from events on demand.
Be careful with Promise.all calls when doing batch operation in MongoDB
This can bring database down quite easily spamming a lot of connections.
Have a safe "shadowing" period during big architectural changes.
Do not do everything in one commit; gradually move to new architecture step-by-step. Have a backup plan to go back one step during dangerous transitions. Often validate consistency of your data while you are between steps.